La Carrera de Relevos del Fraude Moderno: Por Qué las Defensas de Señal Única Están Fallando
Los ataques de fraude modernos evolucionan hacia operaciones complejas y multietapa, parecidas a una carrera de relevos donde diferentes herramientas y actores manejan cada fase. Confiar en defensas de señal única como la reputación de IP o la verificación de correo electrónico deja a las organizaciones vulnerables, ya que los atacantes se adaptan y cambian de tácticas fácilmente.


Los ataques de fraude modernos se asemejan a una carrera de relevos donde diferentes herramientas y actores manejan cada etapa del viaje, desde el registro hasta el cobro.
Cuando solo se inspecciona una señal a la vez, como la IP o el correo electrónico, los atacantes simplemente cambian a una parte diferente de la cadena y aun así tienen éxito.

## Anatomía de una Cadena de Fraude Moderna
Una cadena de ataque típica comienza con la automatización para generar escala. Los atacantes utilizan bots y scripts para abrir un gran número de cuentas con un esfuerzo humano mínimo, a menudo rotando la infraestructura para evitar límites de tasa y reglas de bot simples.
Esos bots suelen estar impulsados por correos electrónicos "envejecidos" o comprometidos y credenciales filtradas, de modo que cada cuenta parezca pertenecer a un usuario de larga data en lugar de algo creado ayer.
Los proxies residenciales enmascaran el tráfico detrás de rangos de IP de consumidores reales, haciendo que el tráfico parezca de usuarios domésticos normales en lugar de centros de datos o servicios VPN conocidos.
Una vez que esas cuentas están establecidas, cambian las tácticas de la automatización a sesiones más lentas y dirigidas por humanos para mezclarse con el uso normal.
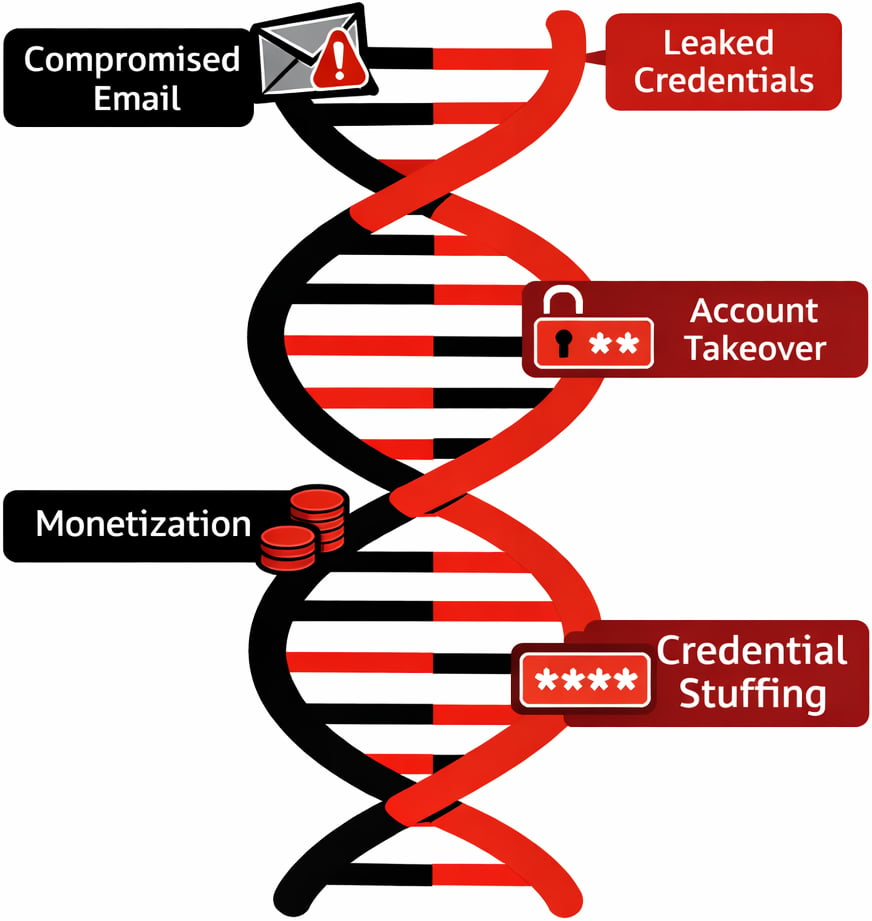
En este punto, la cadena llega a la toma de control de cuentas y la monetización, utilizando enlaces de malware, phishing y resultados de credential stuffing para iniciar sesión, cambiar detalles y realizar transacciones de alto valor.
A lo largo de este ciclo de vida, las herramientas se mezclan y combinan. Un solo actor puede pasar de un navegador sin cabeza y proxy en el registro a un emulador de dispositivo móvil y un proveedor de proxy diferente en el inicio de sesión, y luego ceder el acceso a otra parte que se especializa en agotar fondos o explotar campañas promocionales.
Esto es exactamente por lo que una verificación de señal única en un momento dado rara vez cuenta la historia completa.
## Falsos Positivos por Verificaciones Aisladas
Cuando los equipos se basan en una señal dominante, como la reputación de IP, los falsos positivos se convierten en un problema diario. Los usuarios legítimos en Wi-Fi compartidos, NAT de operadores móviles o VPN corporativas pueden heredar la mala reputación de un pequeño número de malos actores en los mismos rangos, a pesar de que su intención sea limpia.
Bloquear solo por correo electrónico tiene problemas similares, ya que los dominios de correo web gratuitos son utilizados tanto por atacantes sofisticados como por clientes completamente normales.
Los controles centrados en la identidad por sí solos también alcanzan un muro. Las verificaciones de datos estáticos, como coincidencias simples de nombre y documento, son fáciles de falsificar para identidades sintéticas construidas a partir de fragmentos de datos reales.
Los controles centrados en el dispositivo que solo buscan teléfonos rooteados o emuladores pueden pasar por alto a los defraudadores que operan en dispositivos aparentemente normales que han sido comprometidos anteriormente en la cadena. Incluso las soluciones específicas para bots pueden crear puntos ciegos cuando funcionan solas.
Una vez que finaliza una campaña de credential stuffing y los atacantes cambian a inicios de sesión manuales con las mismas credenciales robadas, las herramientas de bot puras solo ven tráfico "humano" y lo aprueban. El resultado es un patrón donde los usuarios de alto riesgo son bloqueados mientras que los adversarios decididos se adaptan y se escabullen.
## Correlación de Múltiples Señales en la Práctica
Una defensa eficaz contra el fraude proviene de la correlación de señales de IP, identidad, dispositivo y comportamiento en cada paso del viaje, en lugar de evaluar cada una de forma aislada.
Una IP que parece ligeramente sospechosa por sí sola se vuelve claramente abusiva cuando se vincula a docenas de cuentas nuevas en la misma huella digital del dispositivo y patrones de comportamiento similares durante la primera sesión.
Del mismo modo, un usuario con un dispositivo aparentemente normal y una reputación de correo electrónico limpia aún puede ser de alto riesgo si el comportamiento de inicio de sesión refleja patrones de credential stuffing o el acceso sigue campañas conocidas de distribución de malware.
Los motores de decisión modernos mejoran la precisión al ponderar cientos o miles de puntos de datos juntos en lugar de aplicar reglas rígidas a un solo atributo.
Para las organizaciones, eso significa unificar lo que antes eran vistas separadas. La inteligencia de IP, la huella digital del dispositivo, la verificación de identidad y el análisis de comportamiento deben alimentar el mismo modelo de riesgo para que cada evento se puntúe en contexto, no como una línea de registro desconectada.
Este enfoque de múltiples señales es la forma más confiable de elevar la barra para los atacantes y al mismo tiempo reducir la fricción para los clientes genuinos.
Prevenga contracargos. Detenga la toma de control de cuentas. Recupere ingresos.
Las principales empresas utilizan los datos de **IPQS** para potenciar sus estrategias de prevención de fraude, no se deje vulnerable. Integre sin problemas con nuestras APIs para reducir la fricción, prevenir más fraudes y asegurar su negocio.
## Caso de Estudio: Deteniendo el Abuso Coordinado de Registro
Considere una plataforma SaaS de autoservicio que ofrece un generoso nivel gratuito y pruebas. A medida que el producto crece, aparece el abuso en forma de miles de registros utilizados para extraer datos, probar tarjetas robadas o revender acceso sin ser detectado.
Las contramedidas iniciales se basan en bloquear ciertos rangos de IP y dominios de correo electrónico desechables obvios, pero esto solo reduce el problema y comienza a afectar a pequeños equipos y freelancers en redes compartidas.
Al cambiar a un modelo de múltiples señales, la plataforma comienza a puntuar los registros combinando IP, dispositivo, identidad y comportamiento.
Las nuevas cuentas que reutilizan la misma huella digital del dispositivo con diferentes correos electrónicos, provienen de IPs vistas recientemente en tráfico automatizado o exhiben inmediatamente un comportamiento de script, se agrupan en clústeres de abuso coordinado en lugar de ser evaluadas una por una.
Esto permite al equipo aplicar respuestas precisas, como desafiar solo a los clústeres de alto riesgo con verificación adicional o limitar silenciosamente sus capacidades, mientras permite que los registros de bajo riesgo procedan sin fricción.
Con el tiempo, los comentarios del abuso confirmado y los usuarios buenos confirmados entrenan el modelo de puntuación, reduciendo los falsos positivos y obligando a los atacantes organizados a gastar más esfuerzo para obtener menos retorno.
## Superando las Tendencias de Fraude
Los atacantes ya no están atados a una sola herramienta o punto débil en su pila. Combinan proxies, bots, identidades sintéticas, credenciales filtradas e infraestructura de malware a través de múltiples etapas, lo que significa que las defensas de señal única siempre irán a la zaga.
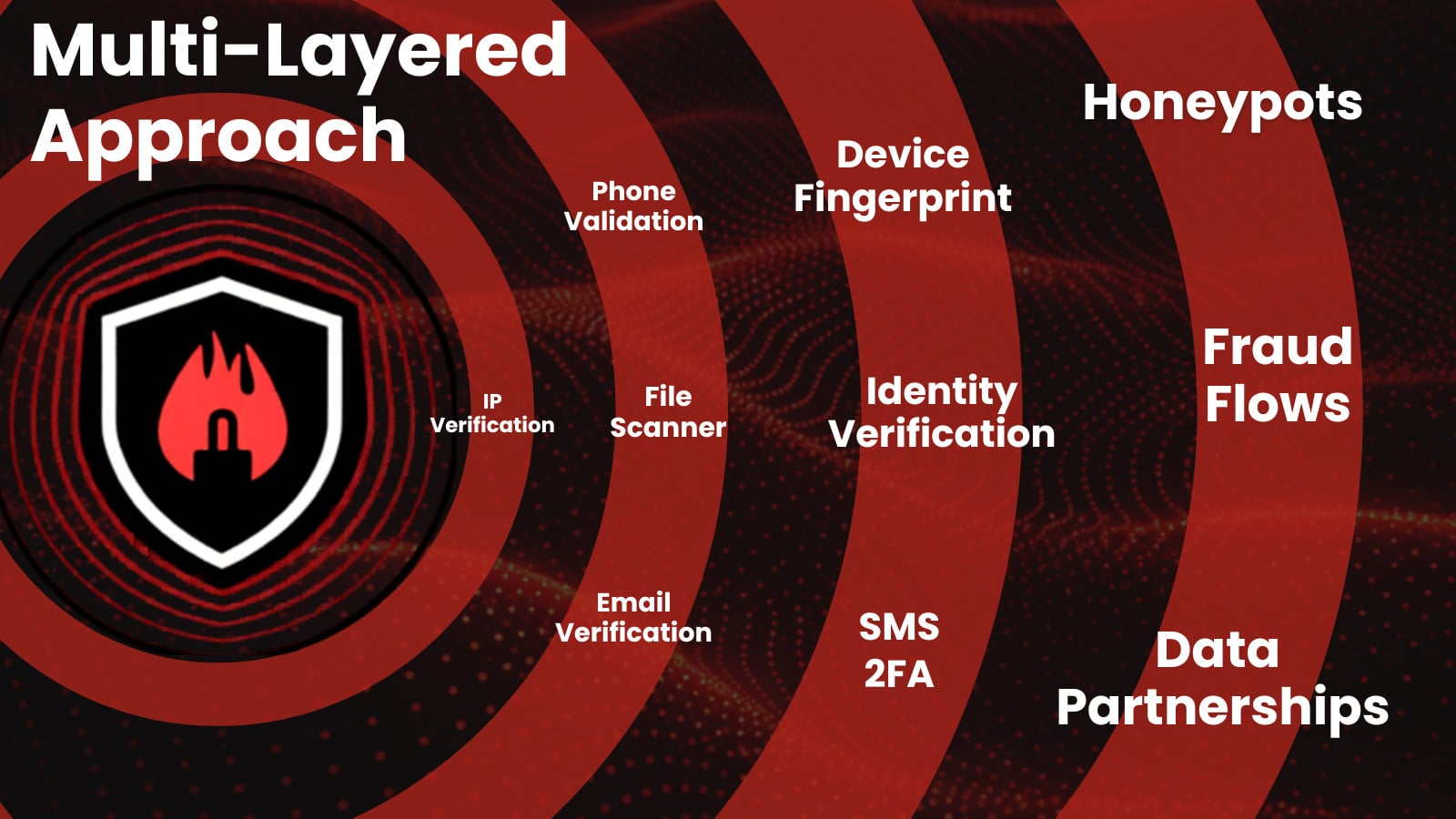
Para mantenerse al día, los equipos de fraude necesitan correlación entre IP, identidad, dispositivo y comportamiento en una vista de riesgo coherente en lugar de una colección de verificaciones desconectadas.
A partir de aquí, la conversación cambia a cómo operacionalizar ese modelo unificado, integrarlo en los flujos de trabajo existentes y medir su impacto tanto en la reducción de pérdidas como en la experiencia del cliente.