A Corrida de Revezamento Moderna Contra Fraudes: Por Que Defesas de Sinal Único Estão Falhando
Ataques modernos de fraude estão evoluindo para operações complexas e multiestágio, semelhantes a uma corrida de revezamento onde diferentes ferramentas e atores lidam com cada fase. Confiar em defesas de sinal único, como reputação de IP ou verificação de e-mail, deixa as organizações vulneráveis, pois os atacantes se adaptam e mudam de tática facilmente.


Ataques modernos de fraude se parecem com uma corrida de revezamento, onde diferentes ferramentas e atores lidam com cada etapa da jornada, desde o cadastro até o saque.
Quando você inspeciona apenas um sinal por vez, como IP ou e-mail, os atacantes simplesmente mudam para outra parte da cadeia e ainda assim obtêm sucesso.

## Anatomia de uma Cadeia de Fraude Moderna
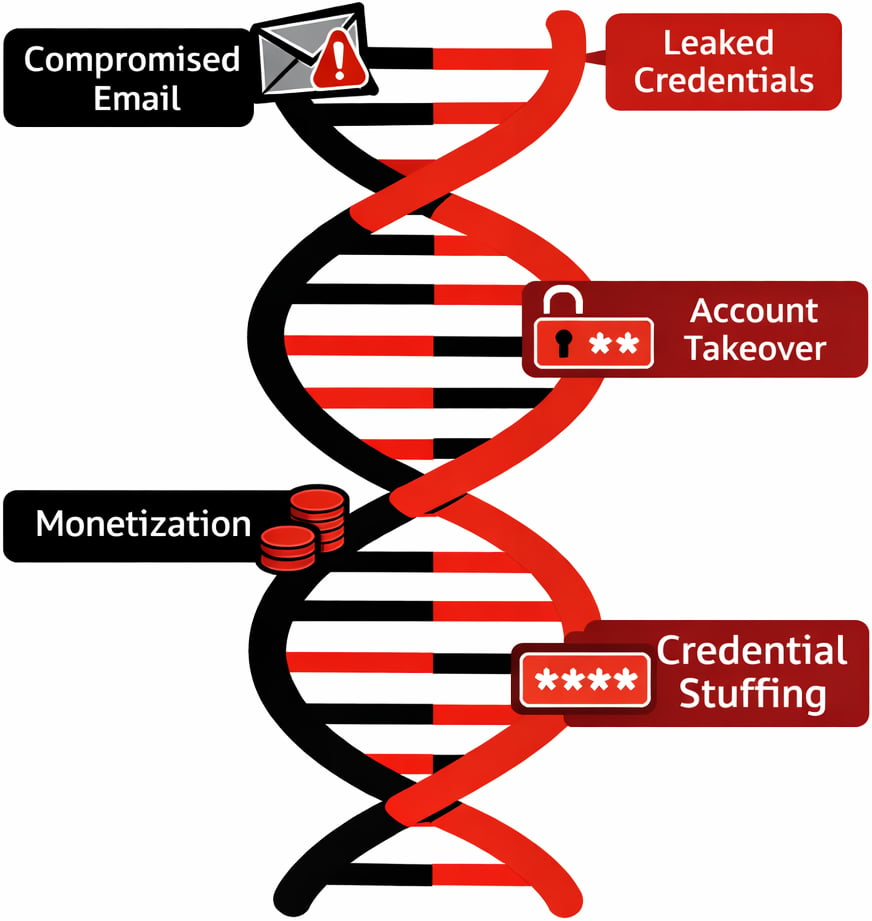
Uma cadeia de ataque típica começa com automação para gerar escala. Os atacantes usam bots e scripts para abrir um grande número de contas com esforço humano mínimo, frequentemente rotacionando a infraestrutura para evitar limites de taxa e regras simples de bot.
Esses bots geralmente são alimentados por e-mails "antigos" ou comprometidos e credenciais vazadas, de modo que cada conta pareça pertencer a um usuário de longa data, em vez de algo criado ontem.
Proxies residenciais, então, mascaram o tráfego por trás de faixas de IP de consumidores reais, fazendo com que o tráfego pareça de usuários domésticos normais, em vez de data centers ou serviços de VPN conhecidos.
Uma vez que essas contas são estabelecidas, eles mudam as táticas de automação para sessões mais lentas e conduzidas por humanos para se misturar ao uso normal.
Neste ponto, a cadeia atinge a tomada de conta e monetização, usando links de malware, phishing e resultados de credential stuffing para fazer login, alterar detalhes e realizar transações de alto valor.
Ao longo deste ciclo de vida, as ferramentas são misturadas e combinadas. Um único ator pode passar de um navegador headless e proxy no cadastro para um emulador de dispositivo móvel e um provedor de proxy diferente no login, e então passar o acesso para outra parte que se especializa em drenar fundos ou explorar campanhas promocionais.
É exatamente por isso que uma verificação de sinal único em um ponto específico raramente conta a história completa.
## Falsos Positivos de Verificações Isoladas
Quando as equipes dependem de um sinal dominante, como a reputação de IP, falsos positivos se tornam um problema diário. Usuários legítimos em Wi-Fi compartilhado, NATs de operadoras móveis ou VPNs corporativas podem herdar a má reputação de um pequeno número de atores maliciosos nas mesmas faixas, mesmo que sua intenção seja limpa.
Bloquear apenas por e-mail tem problemas semelhantes, já que domínios de webmail gratuitos são usados tanto por atacantes sofisticados quanto por clientes completamente normais.
Controles focados em identidade por si só também atingem um muro. Verificações de dados estáticos, como correspondência simples de nome e documentos, são fáceis de falsificar para identidades sintéticas construídas a partir de fragmentos de dados reais.
Controles focados em dispositivos que procuram apenas por telefones roteados ou emuladores podem perder fraudadores operando em dispositivos aparentemente normais que foram comprometidos anteriormente na cadeia. Mesmo soluções específicas para bots podem criar pontos cegos quando funcionam sozinhas.
Uma vez que uma campanha de credential stuffing termina e os atacantes mudam para logins manuais com as mesmas credenciais roubadas, ferramentas puramente de bot veem apenas tráfego "humano" e o aprovam. O resultado é um padrão onde usuários de alto risco são bloqueados, enquanto adversários determinados se adaptam e escapam.
## Correlação de Múltiplos Sinais na Prática
A defesa eficaz contra fraudes vem da correlação de sinais de IP, identidade, dispositivo e comportamento em cada etapa da jornada, em vez de avaliar cada um isoladamente.
Um IP que parece ligeiramente suspeito por si só se torna claramente abusivo quando associado a dezenas de novas contas com a mesma impressão digital do dispositivo e padrões de comportamento semelhantes durante a primeira sessão.
Da mesma forma, um usuário com um dispositivo aparentemente normal e reputação de e-mail limpa ainda pode ser de alto risco se o comportamento de login refletir padrões de credential stuffing ou o acesso seguir campanhas conhecidas de distribuição de malware.
Motores de decisão modernos melhoram a precisão pesando centenas ou milhares de pontos de dados juntos, em vez de impor regras rígidas em um único atributo.
Para as organizações, isso significa unificar o que antes eram visões separadas. Inteligência de IP, impressão digital de dispositivo, verificação de identidade e análise comportamental devem alimentar o mesmo modelo de risco, para que cada evento seja pontuado em contexto, não como uma linha de log desconectada.
Essa abordagem de múltiplos sinais é a maneira mais confiável de aumentar a barra para os atacantes, ao mesmo tempo em que reduz o atrito para os clientes genuínos.
Previna chargebacks. Pare a tomada de conta. Recupere receita.
Empresas líderes usam dados da **IPQS** para impulsionar suas estratégias de prevenção de fraudes, não se deixe vulnerável. Integre-se perfeitamente com nossas APIs para reduzir o atrito, prevenir mais fraudes e proteger seu negócio.
## Estudo de Caso: Parando Abuso Coordenado de Cadastro
Considere uma plataforma SaaS de autoatendimento que oferece um generoso plano gratuito e testes. À medida que o produto cresce, o abuso aparece na forma de milhares de cadastros usados para raspar dados, testar cartões roubados ou revender acesso discretamente.
As primeiras contramedidas dependem do bloqueio de certas faixas de IP e domínios de e-mail descartáveis óbvios, mas isso apenas atenua o problema e começa a impactar pequenas equipes e freelancers em redes compartilhadas.
Ao mudar para um modelo de múltiplos sinais, a plataforma começa a pontuar cadastros em IP, dispositivo, identidade e comportamento em conjunto.
Novas contas que reutilizam a mesma impressão digital do dispositivo com e-mails diferentes, vêm de IPs recentemente vistos em tráfego automatizado ou exibem imediatamente comportamento scriptado são agrupadas em clusters de abuso coordenado, em vez de serem avaliadas uma a uma.
Isso permite que a equipe aplique respostas precisas, como desafiar apenas clusters de alto risco com verificação adicional ou limitar silenciosamente suas capacidades, enquanto permite que cadastros de baixo risco prossigam sem atrito.
Com o tempo, o feedback de abuso confirmado e usuários bons confirmados treina o modelo de pontuação, reduzindo falsos positivos e forçando atacantes organizados a gastar mais esforço para obter menos retorno.
## Superando as Tendências de Fraude
Os atacantes não estão mais presos a uma única ferramenta ou ponto fraco em sua stack. Eles combinam proxies, bots, identidades sintéticas, credenciais vazadas e infraestrutura de malware em várias etapas, o que significa que defesas de sinal único sempre ficarão para trás.
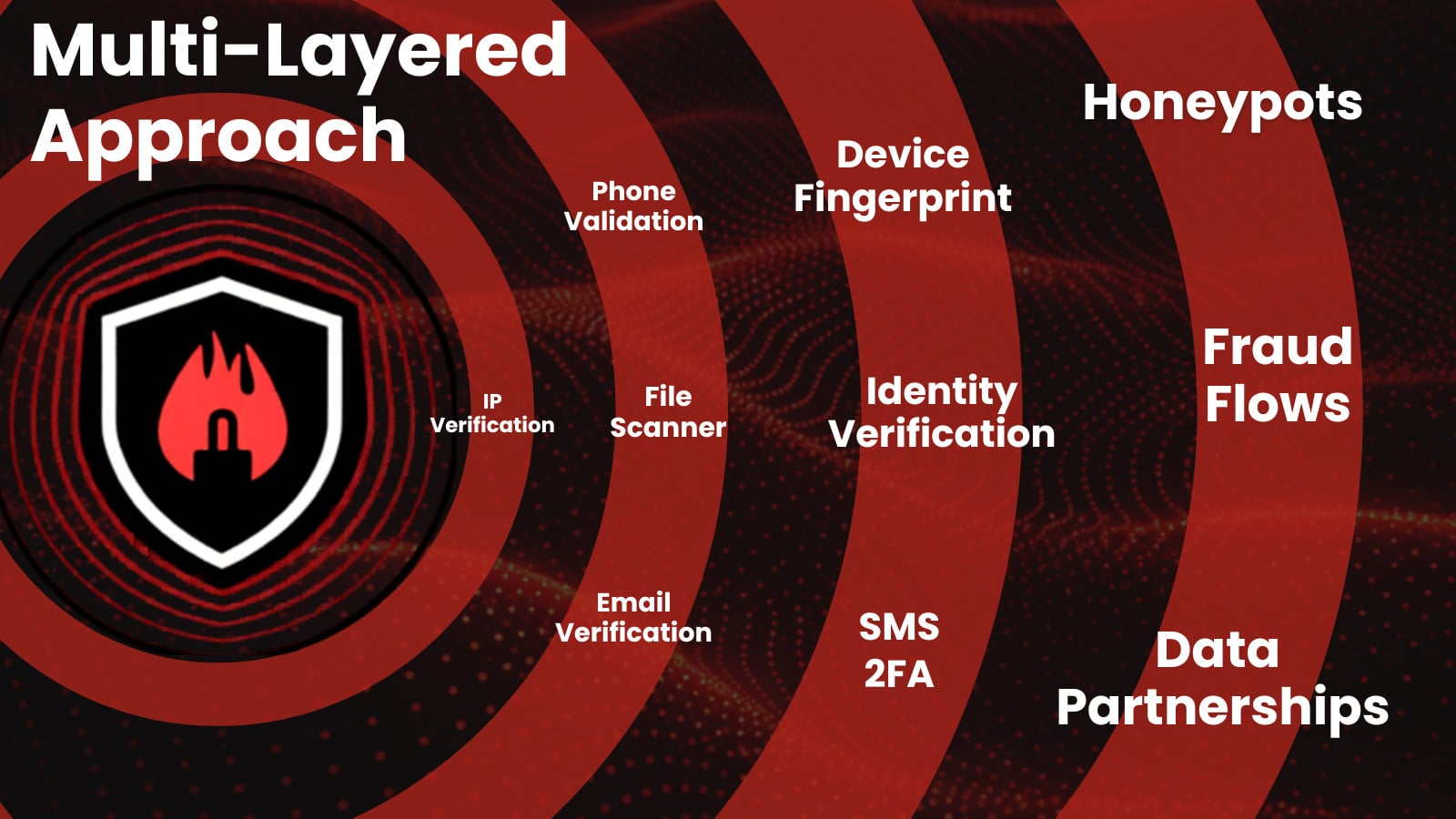
Para acompanhar, as equipes de fraude precisam de correlação entre IP, identidade, dispositivo e comportamento em uma visão de risco coerente, em vez de uma coleção de verificações desconectadas.
A partir daqui, a conversa muda para como operacionalizar esse modelo unificado, integrá-lo aos fluxos de trabalho existentes e medir seu impacto tanto na redução de perdas quanto na experiência do cliente.